

Data Reuse Digest - Spring 2022
Data Reuse Digest - Spring 2022
The first edition of the FAIR CF research newsletter!

Welcome!
Thanks for taking the time to read this newsletter - to learn more about our mission, please go read the FAIR-CF Manifesto.
Here’s how to read this newsletter:
If you’re short on time - Read the study summaries, which are kept under 3 sentences to focus on the basic goals and findings. You can further focus on just those research areas (Cystic Fibrosis, the Lung, the Gut) that are relevant to you, or even focus on specific study outcomes (#Software Tool, #Translational Insights, etc.)
If you’ve got more time on your hands - check out the featured studies themselves and all the tools and data associated with them (follow the links), read through the ‘call to action’, and think about how you can take this quarter’s newsletter and apply it to your own research. We welcome comments and feedback to make this newsletter as useful as possible to the CF research community.
And don’t forget to spread the word to other CF researchers or biologists you know who would benefit from reading. Click the ‘Share FAIR CF’ button at the bottom of the newsletter!
If you’re not subscribed yet - enter your email below to get the newsletter in your inbox every quarter:
News From the Field
Cystic Fibrosis
Scientists develop new software tool to study variability in the agr quorum sensing system across different S. aureus bacterial strains. Their findings improve our understanding of how S. aureus regulates virulence, and how its quorum sensing systems have evolved over time (Tool: AgrVATE; Data Source: Staphopia) [Publication: Emory University]
#Software Tool #Basic Biology Insights
Is the abundance of microbial taxa in the lungs of bronchiectasis patients correlated with disease state? Scientists find that microbial community structure and diversity may help predict disease outcomes (Data Source: NCBI BioProject, 4 Data Sets) [Publication: Xinjiang Medical University]
#Basic Biology Insights
A group of scientists have developed a new tool for metagenome assembly. The tool will speed up the analysis of data from metagenomics experiments, and make metagenomics analysis more accessible to all researchers. (Tool: SprayNPray; Data Sources: 3 prior published studies) [Publication: Multiple Institutions, United States]
#Software Tool
The Lung
Scientists sought to validate a biomarker, S100A12, for interstitial pulmonary fibrosis (IPF). They did so by taking advantage of publicly available data, determining the expression of the molecule in various tissues. They find that S100A12 is indeed useful for gauging IPF disease progression. (Data Source: GEO, 24 Data Sets) [Publication: Multiple Institutions, China] #Translational Insights
How does the immune response impact lung cancer progression? Scientists have shown that the percentage of tumor-infiltrating immune cells, as well as the expression of genes in those cells, is correlated with survival in lung cancer patients. Using a computationally-informed approach like this one to assess patient prognosis can help ensure that cancer patients receive the best personalized treatment. (Data Sources: GEO, 2 Data Sets ; GDC Data Portal) [Publication: Nanjing Medical University] #Translational Insights
Scientists set out to determine the role of ferroptosis (iron-dependent cell death) in the development of IPF. Using data from prior studies, the research team identified a set of 13 up-regulated and 7 down-regulated genes related to ferroptosis in the lung tissue of IPF patients. Further analysis with an IPF mouse model showed that training mice on treadmills reduced ferroptosis gene expression in the lungs - and so it may be true for humans too that aerobic exercise has a positive effect. (Data Sources: GEO, 2 Data Sets, FerrDB, 1 Data Set) [Publication: Chengdu Medical College] #Translational Insights
Researchers show how miRNAs and mRNAs interact in cases of acute lung injury. The research team followed a multi-step process of exploring public data to find differentially expressed miRNAs and mRNAs under experimental conditions that produce acute lung injury, predicting mRNA-miRNA interactions, and then validating these predicted interactions in a mouse model. The biological model of miRNA-mRNA interactions will lay the grounds for future biological experiments that interrogate the individual mRNA and miRNA molecules at play (Data Source: GEO, 3 Data Sets) [Publication: Multiple Institutions, China] #Basic Biology Insights
Researchers set out to monitor the global spread of Scedosporium aurantiacum, a dangerous emerging fungal pathogen. Though the fungus has only been reported publicly in a small number of countries, analysis of existing fungal metabarcoding studies suggests that it has actually been detected in samples from 26 countries and two islands across the world. The fungus is therefore much more prevalent than previously thought. (Data Source: SRA) [Publication: Multiple Institutions, Australia] #Epidemiology
The Gut
Scientists have long sought to understand the 'core gut microbiome' of healthy individuals - and how its disruption may contribute to disease. One shortcoming in this effort, however, is that the majority of microbiome samples collected and analyzed thus far have come from Western countries alone. To start remedying this lack of data diversity, public shotgun sequencing data was used to show that there is indeed a conserved set of microbial taxa across samples from a wide range of global locations (El Salvador, Peru, Madagascar, Japan, China, Oklahoma, and Washington DC). (Data Sources: NCBI NT, NCBI GenBank, EMBL-EBI, ENA) [Publication: University of València] #Diversifying Research
Another study along similar lines asked the question: how well have human microbiome studies sampled the global population? According to this analysis of human microbiome studies in the Sequence Read Archive (SRA), not very well. Almost 50% of samples of known origin were collected in the US - though the US makes up only 4.3% of the global population. The countries of India, Pakistan, and Bangladesh, which make up over 1/4 of the global population, are only represented in 1.8% of human samples. (Data Source: SRA) [Publication: University of Minnesota] #Diversifying Research
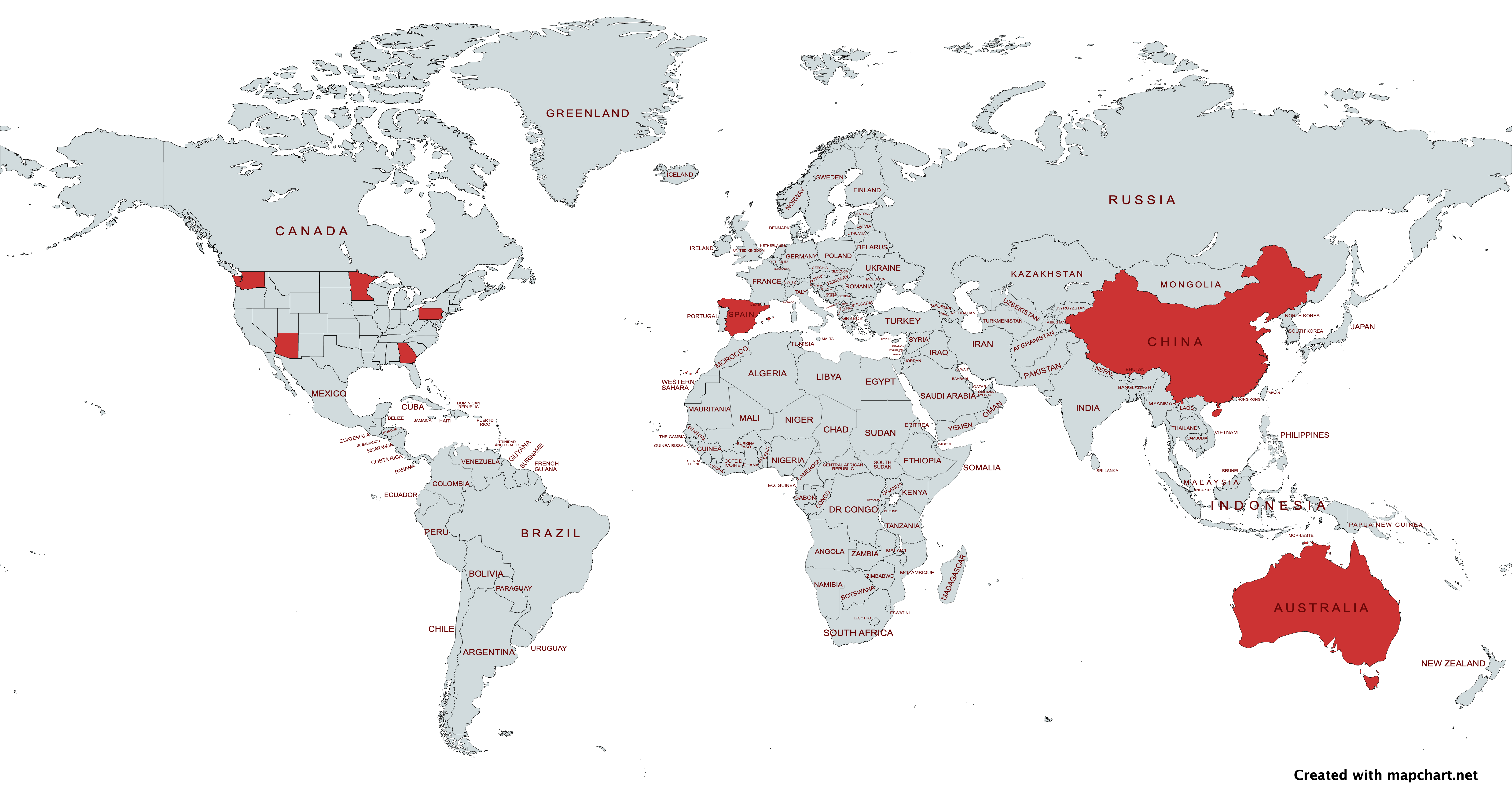
Summary
This quarter’s featured papers utilized 10 public databases (Staphopia ; NCBI Bioproject, GEO, SRA, NT, GenBank ; NCI GDC Data Portal; FerrDB ; EMBL-EBI; European Nucleotide Archive (ENA))
This quarter’s featured papers drew from 38 individual data sets. Follow the links to the publications above if you want to see the data sets used by the authors.
This quarter’s featured papers came from a broad community of researchers working in 5 US States and 3 other countries:
Call To Action
Check out this month’s call to action to see how you can put public data to work in your own research
The Background:
At the start of all data re-use projects is an effort to understand what public data is out there that will help you answer relevant questions about the biological system, organism, or disease(s) that you study. Every project listed in this quarter’s ‘News From the Field’ makes use of some existing data source - often data from large public databases.
The NCBI Databases (GEO, SRA, BioProject, etc.) are a great one-stop shop for public datasets - this is why so many of the articles featured this quarter make use of them. These databases have a whole bunch of experiments related to CF and many other diseases. Sometimes, however, you might want to make use of a database that is more specific - for example, a database devoted to a single CF pathogen (such as Staphopia)
Why is this relevant to you?
Keeping track of what exists in these databases is not just good for a systematic analysis (like those featured in the ‘News From the Field’). Even for non- bioinformatics researchers, public data can inform wet bench experiments. It allows you to discover whether other researchers have performed similar investigations in the past, and to see how your own experimental methods and findings stack up.
Here’s what you can do:
This quarter, we call on you to explore the different databases that are relevant to your work and see what studies are out there. Check out the NCBI databases (for a good tutorial on using GEO, see here. BioProject, SRA, and the other NCBI databases work in a similar way). You should check out more specific databases as well (Staphopia for S. aureus, Pseudomonas.com for P. aeruginosa, etc.). You can trawl through the databases manually, or you can take advantage of software tools that summarize and even analyze existing CF studies of different types (Scan-GEO for MicroArray studies, CF-Seq for RNA-Seq studies).
We encourage you to keep track of what you find. It may prove useful for ongoing or future experiments. You can survey these past studies as a one-time job, or even better, make a plan to check back every three months or so to keep yourself up to date. Once you start doing this regularly, it will become much easier to think about how you can make use of public data in your own lab.
Spread the Word
Thanks for reading! If you want to help us in our mission to help CF researchers make the most of public data, please share this newsletter with any colleagues who would be interested. Just press the button below to share…
We also encourage you to share your experience (successes, challenges, questions) taking part in this quarter’s ‘call to action’ by leaving a comment. We’ll acknowledge the efforts of those who share in future editions of this newsletter.
Nice resource!